Enron: JSON Files

“You don’t want another Enron? Here’s your law: If a company, can’t explain, in one sentence, what it does... it’s illegal.”
Use Python to Analyze Email Corpus
What is Enron?
Enron was a major energy company based on Texas. It was involved with accounting fraud resulting in a scandal that dominated the news in 2001, and eventually ended in the bankruptcy of the company. Enron’s senior management was dismissed and several key individuals were convicted of various crimes and received jail time as well as significant fines.
During the litigation and bankruptcy proceedings, emails sent and received by agents of Enron were collected and preserved. Select e-mails were made available for research. This database is called the Enron Corpus and contains email communication of over 150 employees including that of then CEO, Kenneth Lay.
What are we trying to do?
I did bit of forensic analysis. I wanted to see if I could find email communication to and from the CEO, Ken Lay among the 250,000 emails in the extract. As it turned out, the exercise was tricky because Ken did not usually communicate through his own email account. I wanted to count the messages sent and received by Kenneth Lay, and see who was the lucky person who received the most messages from Kenneth Lay. I also wanted to see who sent the most messages to him. I thought it would be interesting to see if the volumes of Ken’s emails increased or decreased before and after the bankruptcy. We also know that Arthur Andersen, the accounting firm played a significant role in the scandal. So I decided to count the number of messages mentioning Arthur Andersen. And as a last item, I wanted to create a nice graphic from the emails. I created a word cloud to…well, why not?
Let’s go already!
First, we need to load all the necessary packages for this work. The data is available from lots of different sources. Just Google it! I downloaded it and created a pickle for myself. I used the pickle in the analysis.
import pandas as pd import numpy as np import pickle enron_email_df=pd.read_pickle("enron_email_df2.pkl") enron_email_df.shape enron_email_df.head(1)
It appears that Ken communicated through many different emails and he also asked others to send communication in his behalf. Some inspection of the data led to several email addresses. I found that his secretary, Rosalee, sent messages on the CEO’s behalf, but Ken communicated through kenneth.lay@enron.com, ken.lay@enron.com and office.chairman@enron.com email addresses as well. Also, there were some emails from Ken using the enron.announcements@enron.com email address.
kens_mail1= enron_email_df[enron_email_df.From == 'kenneth.lay@enron.com'] kens_mail2= enron_email_df[enron_email_df.From == 'ken.lay@enron.com'] kens_mail3= enron_email_df[enron_email_df.From == 'rosalee.fleming@enron.com'] kens_mail4= enron_email_df[enron_email_df.From == 'enron.announcements@enron.com'] kens_mail5= enron_email_df[enron_email_df.From == 'office.chairman@enron.com'] mail_to_ken1= enron_email_df[enron_email_df.To == 'kenneth.lay@enron.com'] mail_to_ken2= enron_email_df[enron_email_df.To == 'klay@enron.com'] mail_to_ken3= enron_email_df[enron_email_df.To == 'office.chairman@enron.com'] mail_to_ken4= enron_email_df[enron_email_df.To == 'enron.announcements@enron.com'] kens_mail3

A screenshot of Python output: kens_mail3 represents al emails from Ken Lay sent by his secretary, Rosalee Fleming
A Bit More Specific Digging for Emails Sent by Kenneth Lay Under His Own Name:
I first searched for Kenneth Lay’s emails based on typical corporate email nomenclature such as kenneth.lay@enron.com, ken.lay@enron.com, kenneth_lay@enron.com, ken_lay@enron.com, and klay@enron.com.
Kenneth Lay appeared to have sent emails under kenneth.lay@enron.com (n=20) and ken.lay@enron.com (n=1). The other email possibilities tried did not result in the identification of emails sent by the disgraced CEO. Below is a simple code to count some of those emails.
kens_mail1.count() mail_to_ken4.count()
Emails Sent by Kenneth Lay’s Secretary:
During inspection of emails, it became evident that Kenneth Lay’s secretary, Rosalee Fleming (rosalee.fleming@enron.com) was involved with managing his email correspondence. In fact, several emails sent by the secretary contained the following text string in the body of the email: “Rosalee for Ken”. A total of 164,030 such emails were identified, although most of these were repeat emails as a result of email chains and forwards.
kens_mail3b=kens_mail3[(kens_mail3['body'].str.contains('Rosalee for Ken'))] kens_mail3b.count()
Emails Sent Under a Corporate Title (e.g. Chairman):
Further inspection of emails resulted in the identification of several emails that contained the following strings in the body: “On Behalf Of Ken Lay” or “Office Of The Chairman”. Both queries identified a large number of emails: 193,484 (On Behalf Of Ken Lay) and 209,820 (Office Of The Chairman).
enron_email_df['body'].fillna("", inplace=True) kens_mail8=enron_email_df[(enron_email_df['body'].str.contains('Office Of The Chairman'))] kens_mail8.head() kens_mail9=enron_email_df[(enron_email_df['body'].str.contains('From: ENA Office of the Chairman'))] enron_email_df['body'].fillna("", inplace=True) kens_mail8=enron_email_df[(enron_email_df['body'].str.contains('Office Of The Chairman'))] kens_mail8.head() kens_mail9=enron_email_df[(enron_email_df['body'].str.contains('From: ENA Office of the Chairman'))] kens_mail9.head(1)
Select Some Emails for Analysis
Let’s go back to the pkl file for a few seconds. The file enron_email_df2.pkl was ingested and inspected. The file contained 250,758 emails with 13 variables: body, Date From, Message, Subject, To, X-From, X- To, X-bcc, X-cc, mailbox, size, and subfolder.
We already talked about Ken’s emails . Kenneth Lay sent most of his messages from enron.announcements@enron.com (n=4,179), and from office.chairman@enron.com. Rosalee Fleming’s emails were further scrubbed because not all of them were communication of Ken Lay. Finally, the email addresses that received most emails addressed to Kenneth Lay were Kenneth.lay@enron.com (n=693) and klay@enron.com (n=799).
Next, Rosalee Fleming’s email correspondence was filtered for relevant email. Rosalee sent nine emails with Rosalee for Ken in the body of the email. In other words, these emails were Kenneth Lay’s communication but were sent out by his secretary, Rosalee.
Further, several messages were sent out by other individuals, who concluded their email with “On Behalf Of Ken” in the body of the email. There were 45 such instances in the Enron Corpus. However, it was possible that these emails were not original communication but forwarded emails of Ken Lay. Further study was necessary for the 45 emails.
During the forensic phase, it became clear, that Kenneth Lay sent some emails from mailbox with “Ken Lay – Chairman of the Board@ENRON” in the X-From field. The following code revealed, that all of these emails were sent from no.address@enron.com. There were 107 such emails.
Next, inspection of emails revealed that some emails contained “Office Of The Chairman” or “ENA Office of the Chairman” in the body. These emails were selected for further study. There were eight emails with “Office Of The Chairman” and six emails contained “ENA Office of the Chairman” in the body.
The dataframes of each filtered datasets (themselves dataframes) were concatenated. Note that that two different dataframes were created. The first (final_data) contained all emails sent by Kenneth Lay, while the second dataframe contained all emails sent to Kenneth Lay.
final_data=pd.concat((kens_mail1, kens_mail2, kens_mail3b, kens_mail4, kens_mail5, kens_mail7, kens_mail8, kens_mail9)) final_data.head(1) final_data2=pd.concat((mail_to_ken1, mail_to_ken2, mail_to_ken3, mail_to_ken4)) final_data2.head(1) final_data.groupby('From').count()

A quick check of the data frame - final_data - revealed that there were some emails erroneously included in the analysis. These emails were selected during one of the routines that selected emails based on the presence of a specific string. All of the emails marked in red below were removed from the final analytic data set (final_data)
final_data= final_data[final_data["From"] != 'chris.germany@enron.com'] final_data= final_data[final_data["From"] != 'david.delainey@enron.com'] final_data= final_data[final_data["From"] != 'eric.saibi@enron.com'] final_data= final_data[final_data["From"] != 'geoff.storey@enron.com'] final_data= final_data[final_data["From"] != 'ina.rangel@enron.com'] final_data= final_data[final_data["From"] != 'joe.quenet@enron.com'] final_data= final_data[final_data["From"] != 'mark.pickering@enron.com'] final_data= final_data[final_data["From"] != 'shelley.corman@enron.com'] final_data= final_data[final_data["From"] != 'trevor.woods@enron.com'] final_data.groupby('From').count()
Count No. of Emails Before and After Bankruptcy
The goal of the analysis was to understand whether more or fewer emails were sent by Ken Lay before and after the date when Enron declared bankruptcy. Note that the date of Enron’s bankruptcy was December 2, 2001.
The Date column was first transformed from object to datetime format. This was accomplished for both final_data and final_data2 dataframes, which represent the emails from and to Kenneth Lay, respectively.
from datetime import datetime from dateutil.parser import parse import pandas as pd final_data['Date'] = pd.to_datetime(final_data['Date']) final_data['Date'] final_data2['Date'] = pd.to_datetime(final_data2['Date']) final_data2['Date']
Next, an object was created signifying Enron's bankruptcy date of 2001 December 2, 2001. In this process, a string was first created (2001,12, 2). The string signifying Enron’s bankruptcy date was then transformed to a timestamp using a datetime format.
The bankruptcy date was compared against each emails' timestamp in the Date column. If an email's timestamp was before the bankruptcy date, a code 1 was issued, while an email timestamp earlier than the bankruptcy date was coded as 0 in a column called new. The procedure was done with both final_data (emails from Kenneth Lay) and final_data2 (emails to Kenneth Lay).
from datetime import date bankrupt=date(2001,12,2) bankrupt_date=pd.to_datetime(bankrupt) #convert to datetime from string bankrupt_date bankrupt_date final_data.insert(2,'new', np.where(final_data['Date']>bankrupt_date, 1, 0)) final_data2.insert(2,'new', np.where(final_data2['Date']>bankrupt_date, 1, 0)) final_data['new'].value_counts()
Finally, the number of emails sent from and to Kenneth Lay before and after the bankruptcy date were counted. Kenneth Lay sent 4,737 emails before December 2, 2001, but sent only two after Enron applied for bankruptcy protection. He also received 836 emails pre-bankruptcy and 659 emails post-bankruptcy. Interestingly, Kenneth Lay resigned from the company three weeks after the bankruptcy date, yet the number of emails he received during this time period is significant. A graphical representation of the data was also prepared.
import numpy as np import matplotlib.pyplot as plt N=2 Pre_bankruptcy=(4737, 2) ind = np.arange(N) # the x locations for the groups width = 0.35 # bar width fig, ax = plt.subplots() rects1 = ax.bar(ind, Pre_bankruptcy, width, color='r') Post_bankruptcy = (836, 659) rects2 = ax.bar(ind + width, Post_bankruptcy, width, color='y') # Labels, title and ticks added to graph ax.set_ylabel('No. of emails') ax.set_title('No. of Emails Sent to/from Ken Lay') ax.set_xticks(ind + width / 2) ax.set_xticklabels(('Pre-bankruptcy', 'Post-bankruptcy')) ax.legend((rects1[0], rects2[0]), ('Emails from Ken Lay', 'Emails to Ken Lay')) def autolabel(rects): """ Attach a text label above each bar displaying its height """ for rect in rects: height = rect.get_height() ax.text(rect.get_x() + rect.get_width()/2., 1.05*height, '%d' % int(height), ha='center', va='bottom') autolabel(rects1) autolabel(rects2) plt.show()
No. of Emails Sent to/from Ken Lay
final_data['body'].fillna("", inplace=True) Arthur_Andersen=final_data[(final_data['body'].str.contains('Arthur Andersen'))] Arthur_Andersen.count()
Count No. of Emails with Arthur Andersen in the Body
The total number of emails with Arthur Andersen explicitly discussed in Ken Lay’s emails was 12. This finding is specific to the emails sent by Ken Lay since only the final_data dataframe was used in this analysis.
Where did Ken Get Most of His Emails from?
When considering the emails sent by Ken Lay, the most frequently appearing recipient was identified. Separately, focusing only emails received by Ken Lay, the entity sending the largest number of emails was also identified. It appears that Ken Lay rarely sent emails to individuals but rather used companywide communication when using email. He sent 1,375 emails to all.wordlwide@enron.com , which appears to be a company wide distribution list. As for the most frequent senders to Ken Lay, Steven Kean (steven.kean@enron.com) sent 26 emails, which was the most frequent in the dataset.
count_to=final_data.groupby('To').count() count_to.sort_index(by=['body'], ascending=[False]) count_from=final_data2.groupby('From').count() #where did Ken receive his emails from #count_from_df=pd.DataFrame(count_from) count_from.sort_index(by=['body'], ascending=[False])

Final Code for Fun
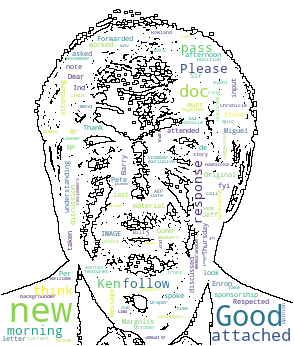
The last issue I wanted to show with the Enron Corpus is a word cloud. One can call it a type of sentiment analysis. First, I created two wordclouds using the words in Ken’s emails. Lastly, I got a picture of Ken from the Internet and used its contour (mask) to create a wordcloud to resemble Ken. At least as much as possible!
First the data was saved a string, and tokenized into a list of sentences as well as into a list of words. This was done separately for final_data and final_data2.
import pandas as pd import numpy as np import nltk nltk.download('punkt') nltk.download('stopwords') from nltk.tokenize import sent_tokenize, word_tokenize from nltk.corpus import stopwords from string import punctuation final_data_str=repr(final_data.body) #the dataframe is transferred to a string final_data2_str=repr(final_data2.body) #the dataframe is transferred to a string
I then tokenized the data. The first represents the result of the sentence tokenization, while the second is the result of word tokenization. Again, this was done separately for final_data and final_data2. I am only showing a portion of the output to save some space.
sentences = sent_tokenize(final_data_str) # tokenize comments into a list of sentences sentences sentences2 = sent_tokenize(final_data2_str) # tokenize comments into a list of sentences sentences2 #(only sentences are shown below)

Stop words and a list of punctuation was applied so that filler words and punctuation do not appear in the wordcloud.
#before tokenizing, clean the list of punctuation import string string.punctuation

The most frequently appearing words were counted among the list of tokenized words. The same was accomplished with the filtered words, e.g. the list devoid of stopwords and punctuation. This was accomplished using a counter.
content = "".join(sentences).replace('\\n', " ").replace('\\t', " ").replace('\n', " ") for d in string.punctuation: content=content.replace(d, " ") content content2 = "".join(sentences2).replace('\\n', " ").replace('\\t', " ").replace('\n', " ") for d in string.punctuation: content2=content2.replace(d, " ") content2

The top image shows the most frequently used words in the emails sent by Ken Lay. The bottom image represents frequent words in the emails sent to Ken Lay.
words = word_tokenize(content) # tokenize comments into a list of words words words2 = word_tokenize(content2) # tokenize comments into a list of words words2 cust_stop_words = set(stopwords.words('english')+list(punctuation)) # stop words + punctuation cust_stop_words filtered_words = [word for sent in words for word in word_tokenize(sent) if word.lower() not in cust_stop_words] filtered_words filtered_words2 = [word for sent in words2 for word in word_tokenize(sent) if word.lower() not in cust_stop_words] filtered_words2 fw_freq = nltk.FreqDist(filtered_words).most_common() # using nltk to get word frequencies fw_freq fw_freq2 = nltk.FreqDist(filtered_words2).most_common() # using nltk to get word frequencies fw_freq2 predefined=['ho', 'th', 'w', 'h', 'ge', 'L', '10' ] fw_freq3 = [i for i in fw_freq if i[1] > 0 and i[0] not in predefined] #we canchange the frequency from 0 to limit the number of words fw_freq3b = [i for i in fw_freq2 if i[1] > 0 and i[0] not in predefined] fw_freq4 = [i for i in fw_freq3 if i[0].strip(string.punctuation) != ''] fw_freq4b = [i for i in fw_freq3b if i[0].strip(string.punctuation) != ''] fw_freq5 = [i[0].replace('\\n', '') for i in fw_freq4] fw_freq5 fw_freq5b = [i[0].replace('\\n', '') for i in fw_freq4b] fw_freq5b from collections import Counter Counter(fw_freq5).most_common(5) Counter(fw_freq5b).most_common(5)
And now we are ready for the wordclouds:
import wordcloud #install wordcloud and import all package necessary for wordcloud from scipy.misc import imread import matplotlib.pyplot as plt import random from wordcloud import WordCloud #create a single string from list send_list=' '.join(fw_freq5) wordcloud=WordCloud(width=1800, height =800, background_color="white", min_font_size=5, random_state=42).generate(send_list) plt.figure(figsize=(18,8), facecolor = None ) plt.imshow(wordcloud) plt.axis("off") plt.tight_layout(pad=10) plt.show()

from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt import os from wordcloud import WordCloud, STOPWORDS d = path.dirname(__file__) if "__file__" in locals() else os.getcwd() ken_mask = np.array(Image.open(path.join(d, "ken_lay2.png"))) wc = WordCloud(background_color="white", max_words=2000, mask=ken_mask, contour_width=0.3, contour_color='black') text = send_list # generate word cloud wc.generate(text) # store to file wc.to_file(path.join(d, "ken_lay2.png")) # show plt.figure(figsize=(18,18), facecolor = None ) plt.imshow(wc, interpolation='bilinear') plt.axis("off") plt.figure() plt.imshow(ken_mask, cmap=plt.cm.gray, interpolation='bilinear') plt.axis("off") plt.show()